В финансовом секторе Excel-файлы часто используют как самостоятельное программное обеспечение. Разберем ошибки разработчиков, которые влияют на эффективность использования электронных таблиц.
Почему сложные таблицы часто бесполезны
В компании «Финансовый Гений» работал аналитик Александр, известный аналитическими способностями и умением создавать сложные модели в электронных таблицах. Однажды Александр решил разработать модель для анализа инвестиционных портфелей.
Александр уделил модели много времени и сил, вложив в нее все свои знания и опыт. Он использовал много финансовых формул, сводных таблиц и графиков для визуализации данных. Получилась сложная и мощная таблица для детального анализа инвестиционных возможностей.
Александр представил модель руководству, утверждая, что она значительно улучшит процесс принятия инвестиционных решений и увеличит прибыльность портфеля. Руководство восхитилось его работой и решило внедрить модель.
После внедрения выяснилось, что сотрудникам сложно понять и использовать таблицу Александра. Многие аналитики не могли правильно интерпретировать данные, что привело к ошибкам в анализе и принятии решений.
Более того, из-за сложности модели возникли проблемы с обновлением данных и поддержкой ее актуальности. Это привело к тому, что информация, получаемая из таблицы, стала менее достоверной и полезной для принятия решений.
В итоге модель Александра, хоть и была мощной и продвинутой, оказалась неэффективной из-за своей сложности и непригодности для широкого использования в финансовой организации. Этот случай стал для компании уроком: он показал, что нужно учитывать не только качество модели, но и ее доступность и простоту для всех сотрудников.
Разберем три непредвиденных последствия использования таблицы Александра на уровне формул в Excel, где Александр допустил ошибки.
1. Сложность интерпретации данных
Причина: Александр использовал сложные финансовые формулы и сводные таблицы, которые было трудно понять другим сотрудникам.
Пример формулы: сложные формулы с использованием массивов типа SUMPRODUCT вместе с аргументами в виде массива значений в формуле ({}), которые требуют специализированных знаний для правильной интерпретации.
Попытка исправления:
– Руководство провело обучение сотрудников по использованию сложных формул и сводных таблиц.
– Были созданы инструкции и руководства по работе с моделью для улучшения понимания данных.
– Проведены индивидуальные консультации с сотрудниками для разъяснения сложных аспектов модели.
НО: обучение сотрудников не учитывало, что уровень знания Excel у них разный. Например, сотрудникам, не имеющим опыта работы с формулами, были даны инструкции по использованию сложных функций типа SUMPRODUCT. Сотрудник «заучил», как использовать эту функцию, но не мог применять более простые функции типа СУММЕСЛИ, что делало разрыв в компетенциях критичным.
2. Проблемы с обновлением данных
Причина: Александр не предусмотрел автоматизированные механизмы обновления данных в модели.
Пример формулы: жестко закодированные ссылки на ячейки, что затрудняет обновление данных без изменения формул.
Попытка исправления:
– Руководство пыталось автоматизировать процесс обновления данных, внедрив макросы и скрипты.
– Были созданы шаблоны для обновления данных с подробными инструкциями.
НО: макросы были написаны без должной проверки на ошибки, что привело к некорректному обновлению данных. Например, макрос мог случайно заменить все значения в столбце, если пользователь сдвинул ряд и добавил колонку. Получились десятки файлов с разными версиями данных, в которых все запутались.
3. Неэффективность использования модели
Причина: Александр не учел потребности других пользователей и создал модель, ориентированную только на его потребности.
Пример формулы: непонятные именованные диапазоны и сложные условные формулы, которые затрудняют использование модели другими сотрудниками.
Попытка исправления:
– Руководство провело опросы сотрудников, чтобы выявить проблемные моменты в использовании модели.
– Были проведены совещания и обсуждения с сотрудниками для выработки рекомендаций по улучшению модели.
– Предпринята попытка внедрить упрощенную версию модели с минимумом сложных функций.
НО: все это привело к потере важных функций для определенных пользователей, что сделало модель менее полезной. Сотрудники, которые реально могли использовать модель, делать это перестали.
Два года мучений – и все бесполезно. Почему? Научный ответ дали исследователи из Университета Сан-Франциско Томас Гроссман и Виджай Мехротра, представив на ежегодной конференции EuSpRIG (Европейской группы по изучению рисков электронных таблиц) статью о таксономии аналитических моделей электронных таблиц. Их классификация охватывает все множество таблиц, которые можно встретить в литературе.
В помощь разработчику: новая классификация электронных таблиц
Критерии классификации
При разработке классификации авторы руководствовались двумя критериями:
1. Сценарий использования (use case) таблицы – конкретная ситуация, в которой может использоваться таблица.
2. Инженерные ресурсы на ее разработку.
Ранее они предложили три основных вида таблиц:
1. Таблица для личного пользования.
2. Аналитическая модель (таблица, которую регулярно использует кто-то кроме разработчика).
3. Приложение (решение для широкого круга пользователей).
Новая классификация представляет собой двумерную матрицу: по горизонтали – сценарии использования, по вертикали – инженерные ресурсы.
Сценарии использования
Сценарии использования таблиц делятся на три варианта:
1. Уникальный анализ. Такая таблица:
– делается для выполнения одного расчета, на короткое время или для частной ситуации;
– используется только разработчиком или (в редких случаях) небольшой командой.
2. Встраивание в бизнес-процессы. В данном случае таблица:
– используется регулярно как часть бизнес-процесса;
– передается владельцу бизнес-процесса, используется им и командой, работающей с бизнес-процессом.
3. Применение таблицы. В этом случае:
– таблицей активно пользуется неограниченное число людей;
– цели ее использования четко не определены.
Инженерные ресурсы
Инженерные ресурсы также делятся на три варианта:
1. Низкий уровень:
– на создание таблицы уходит мало средств и разрабатывается она быстро;
– разработчик не следует каким-либо стандартам.
2. Средний уровень:
– на разработку таблицы уходит умеренное количество средств и времени;
– определенное внимание уделяется стандартам разработки.
3. Высокий уровень:
– на разработку тратятся значительные средства и время;
– используются строгие стандарты разработки.
Таксономия электронных таблиц
Итак, у нас получается девять вариантов:
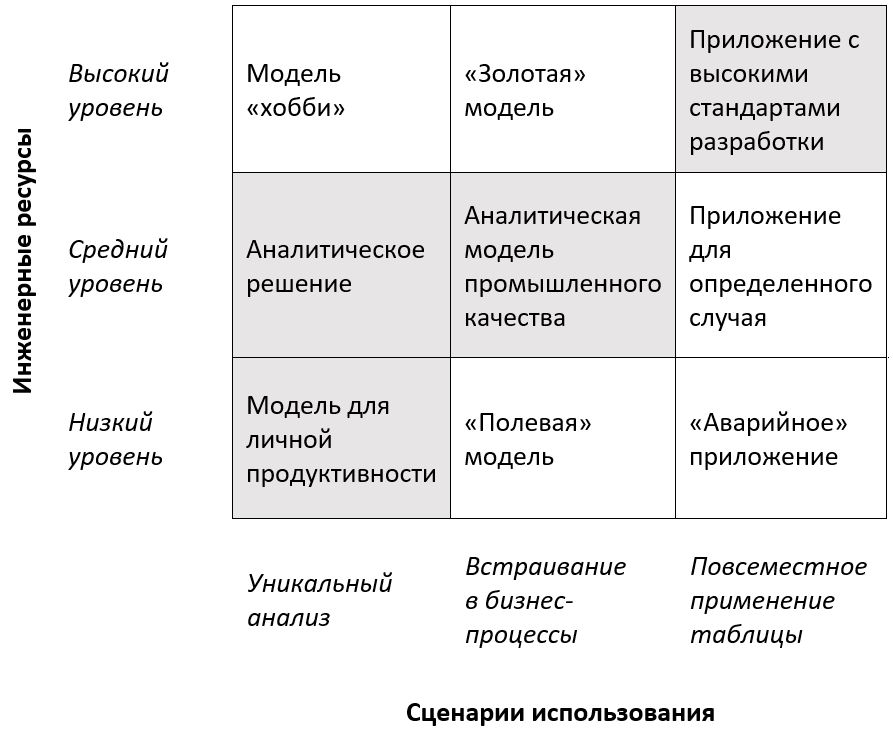
Серым выделены ячейки, которые более часто встречаются в литературе, чем остальные.
Кратко разберем каждый из девяти типов.
1. Аналитическая модель промышленного качества. Эта модель сочетает в себе шесть характеристик: подходит для эффективного анализа; читаема (т.е. понятна людям, не знакомым с разработкой таблиц); переносима; точна; повторно используема; модифицируема.
2. «Золотая» модель. Создание такой модели целесообразно, если вам точно не известен круг возможных пользователей.
3. «Полевая» модель. Подходит для случая, когда лучше быстро получить (и при необходимости передать известным вам пользователям) не слишком проработанную модель, чем не иметь вообще никакой модели.
4. Аналитическое решение. Из шести свойств, присущих аналитической модели промышленного качества (см. п. 1), в аналитическом решении можно найти только три: пригодность для эффективного анализа; точность; возможность повторного использования.
5. Модель «хобби». В эти таблицы вкладываются дополнительные инвестиции, чтобы обеспечить их надежность и использование по назначению. Однако, как правило, такие таблицы использует только разработчик, поэтому затраченные ресурсы могут показаться чрезмерными. Отсюда и название «хобби». На самом деле для создания подобных таблиц могут быть веские причины – например, потребность в некоем резерве для возможного развития.
6. Модель для личной продуктивности. Это быстро разработанная «грязная» модель для однократного применения. Интересно, что авторы данной классификации считают этот вариант самым распространенным.
7. Приложение с высокими стандартами разработки. Это модель, которая создана для широкого круга пользователей. Именно поэтому она требует серьезных инженерных ресурсов – чтобы предотвратить возможное изменение исходного кода и обеспечить отсев входящих данных, способных привести к ошибкам.
8. Приложение для определенного случая. В таких таблицах, как правило, отсутствуют защита исходного кода и отсев некорректных данных на входе. Поэтому при их применении неквалифицированными пользователями возникает определенный риск.
9. «Аварийное» приложение. Это приложение, не соответствующее никаким стандартам и пригодное, по сути, только для использования разработчиком. Веских причин для разработки таких приложений не существует, а риск ошибок и неправильного использования очень высок.
Модели могут переходить из одной категории в другую либо в результате целенаправленного их изменения, либо естественным путем. Первый случай – это переход вверх в том же столбце или по диагонали вверх и вправо. Второй – перемещение вправо в той же строке (т.е. более широкое распространение модели без дополнительных затрат инженерных ресурсов). Второй случай авторы исследования считают нежелательным.
Подведем итог
Применение этой классификации помогает не только избежать излишних затрат ресурсов, но и более эффективно управлять рисками.
Абсолютно недопустимо массово использовать «стихийное» Excel-приложение, которое является критичным для процессов компании, но на которое не затрачены инженерные ресурсы по профессиональной разработке.
Да, такие «времянки» в Excel прочно вошли в российскую практику, и без них уже никто не может обойтись. Если это ваш кейс – то мы поможем избавиться от «времянки» хирургическим путем и предложим профессиональную замену, возможно даже в той же табличной среде.