Многие датасаентисты думают, что стоит скачать библиотечку, нажать кнопку - и все заработает. Но с каждой библиотекой надо разбираться. Расскажем, как.
Если в вашем банке моделями занимаются 1-2 человека, open source - вопрос номер один. Давайте посмотрим: есть ли на github готовые библиотеки, чтобы и скоринговую карту под ключ получить, и от регулятора отбиться, при этом с высоким коэффициентом Gini?
- Monotonic-WOE-Binning-Algorithm
Автор: John Selvam/jstephenj14
Аналог на R: smbinning.
Плюс:
- Претендует на первое место в Python-среде по монотонному биннингу. Избавляет от головной боли, вызванной требованием ЦБ не допускать пересечения бинов по ряду статистических метрик и обеспечить монотонность параметра WOE (Weight of Evidence). Плохой пример слева, хороший справа.
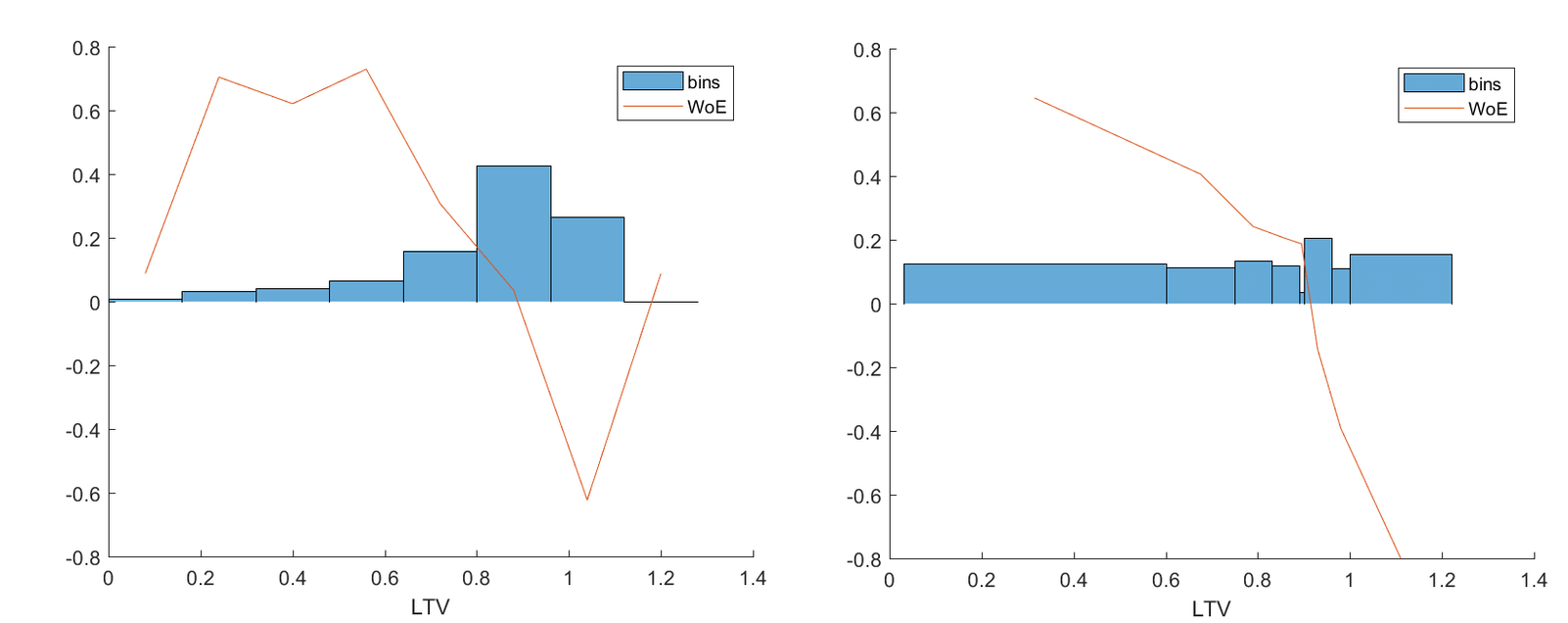 Из статьи Monotone optimal binning algorithm for credit risk modeling
Из статьи Monotone optimal binning algorithm for credit risk modeling
Параметр WOE показан красной линией. Монотонность достигается подбором бинов разной ширины. Получается, что в каждом бине своя точка WOE, который либо падает, либо растет.
Минусы:
- Может вообще не разбинить на выборке с выбросами (активно используются нормальное распределение и дисперсия).
- Не содержит PD-тренд в качестве constraint’а. Полученные бины могут разойтись с логикой.
- Практически нет нужных constraint’ов на количество бинов. У вас может получиться, например, 10 бинов. Для МФО это нормально. Для банка, чтобы модель стабильно использовалась 3-4 года, должно быть примерно 4 бина. У вас всего 12-15 признаков в скоркарте должно быть, чтобы потом защититься от всех контрольных и надзорных органов.
- Содержит три вложенных цикла. Если признаковое пространство большое, придется ставить библиотечку на ночь.
Резюме: доработать не получится.
- XuniVerse
Автор: Sundar Krishnan/Sundar0989
Под капотом библиотеки - qcut pandas. Поэтому все бины одного размера. Она разбивает, например, на бины от 20 до 1, пока ранговая корреляция WOE в этих бинах не будет равна 1. Так устроены еще несколько сходных библиотек.
Плюсы:
- Простая и часто используется.
- Модуль XVerse полностью совместим с трансформаторами sklearn, поэтому их можно использовать в пайплайнах или ваших скриптах. (Сейчас он поддерживает только датафреймы pandas.)
Минус:
- WOE внутри перевернут. Вы об этом догадаетесь, только если вспомните канонические определения.
 Сверьте с документацией SAS прежде чем применять этот код
Сверьте с документацией SAS прежде чем применять этот код
Предпоследняя строчка temp_woe - это исходный код: temp_woe[‘Event_Distribution’] \ temp_woe[‘Non_Event_Distribution’] А должно быть наоборот.
Резюме: если не считать перевернутый WOE, библиотеку можно доработать и применять.
- optbinning
Автор: Guillermo/guillermo-navas-palencia
Самая “суровая” библиотека из всех. Написана чистым математиком, в отличие от предыдущих библиотек, которые писали датасаентисты, рисковики или банковские специалисты.
Плюс:
- Самая гибкая и универсальная библиотека: здесь и WOE-тренды, и все остальное.
Минусы:
- Вместо тех бинов, которые хотите получить вы (или заказчик), выходят какие-то другие, “кривые”.
- Библиотеку сложно включить в пайплайн, потому что не соблюдаются ограничения комплексного биннинга (при включении признака коэффициент Gini должен увеличиваться, интервалы Вильсона не должны перекрываться по WOE и пр.). Может быть, на одной фиче из пятнадцати она и сработает. Но не более.
- Возможно, дело в том, что надо менять исходный код. Но сфоркать и доработать вряд ли получится, по крайней мере в сжатые сроки: в исходном коде больше 30 тысяч строк.
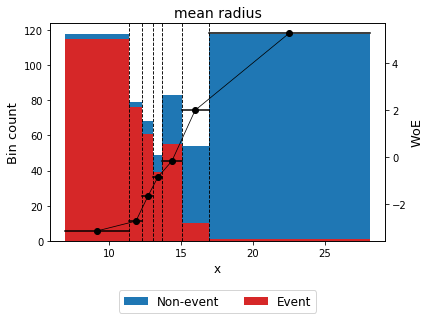 Тренд по WOE выставляется шириной бинов. Но зачастую это не соответствует интервалам, полученным от бизнеса
Тренд по WOE выставляется шириной бинов. Но зачастую это не соответствует интервалам, полученным от бизнеса
Резюме: библиотека с большими перспективами, но не всегда “взлетает”.
- scorecardpy
Автор: Shichen/ShichenXie
Аналог scorecard на R, но дает другие результаты. Очень популярна, особенно среди студентов. На github по запросу “скоринг” выпадает первой.
Плюс:
- Решение “все в одном”. Разделяет выборку на test/train, выбирает за вас все фичи по Information Value, по фильтрам, делает биннинг с разными функциями, скоринговую карту, PSI-метрики и пр.
 Заявленная функциональность
Заявленная функциональность
Казалось бы, идеально. Будущее опенсорса! И первое, что делает начинающий моделист, - сразу ее применяет. А зря, потому что каждый компонент здесь “со странностями”.
Минусы:
- WOE опять перевернут.
- Gini рассчитывается неправильно из-за некорректной работы функции perf_eva:
if np.mean(pred) < 0 or np.mean(pred) > 1: pred = -pred
- KS рассчитывается некорректно.
- Совместима только со sklearn.
- Много багов.
- Бывают сложности в общении с разработчиком.
 Библиотека еще не набрала критическую массу пофиксенной обратной связи
Библиотека еще не набрала критическую массу пофиксенной обратной связи
Резюме: на практике работать с библиотекой не получится либо придется ее переписывать полностью.
-
Наша реальность...
Как видим, наша реальность - pandas и scikit-learn. Но и они предоставляют широкие возможности тем, кто их хорошо изучил.
Например, в pandas, помимо традиционных табличных функций, есть:
- Возможность писать SQL-код, как для формирования таблиц, так и после их формирования для составления выборок.
- Довольно богатые возможности мультииндексирования, которые будут полезны, если у вас много агрегаций по интервалам дат.
- Простой, умный и богатый параметрами импорт-экспорт из основных типов первичных данных.
- Интеграция с большинством стат.пакетов Питона из "коробки".
- Метаклассы или аксессоры - с их помощью можно делать версионирование или по крайней мере “зашить” в колонку кусок кода, который исполняет создание колонки. Потому что когда у вас, например, 1000 фичей и 100 рабочих блокнотов, в какой-то момент всегда хочется спросить: откуда это взялось и как это было рассчитано?
В scikit-learn есть:
- Возможность на лету менять солверы. “В коробке” их 5-6, и они дают разные Gini - каждый солвер нацелен на свое признаковое пространство.
- Лассо-регуляризация, гиперпараметры этой лассо-регуляризации и много других интересных вещей “из коробки” - больше, чем, например, в MATLAB.
- Беспроблемная сериализация и большое число общих для всех видов классификаторов методов, доступных по api.
Однако даже если вы работаете с библиотеками, которые годами завоевывали свою популярность и, как следствие, стабильность в применении, и даже если вы внимательно читаете документацию, вы не застрахованы от тяжелейших ошибок, которые не заметны невооруженным глазом и не покрыты документацией.
Пример.
В документации к pandas.Series.value_counts показано, что параметр bins используется как "convenience for pd.cut, only works with numeric data".
Однако попытка сделать вот так:
categ, bins = pd.cut(pd.Series(arr), bins = 40, retbins=True)
res=pd.Series(arr).value_counts(bins = bins)
где arr - это обычный питоновский массив,
приведет к совсем другому результату, чем очевидный:
pd.DataFrame(arr).groupby(pd.cut(pd.Series(arr), bins = 40)).count()
Речь идет об ошибках на порядок. В первом случае бины будут смещены, несмотря на "convenience" и "retbins".
Усугубляет проблему (как часто бывает) то, что код исполняется без ошибок и предупреждений.
Что "лечит" эти проблемы, которые могут встретиться внутри каждой функции?
Мы используем двухфакторное ноу-хау, которое позволяет проблемам очень быстро всплыть. И если они появляются - первым делом надо проверить исходный код библиотеки.
В нашем случае причина контринтуитивна. Вот это мы находим в pandas/pandas/core/algorithms.py/
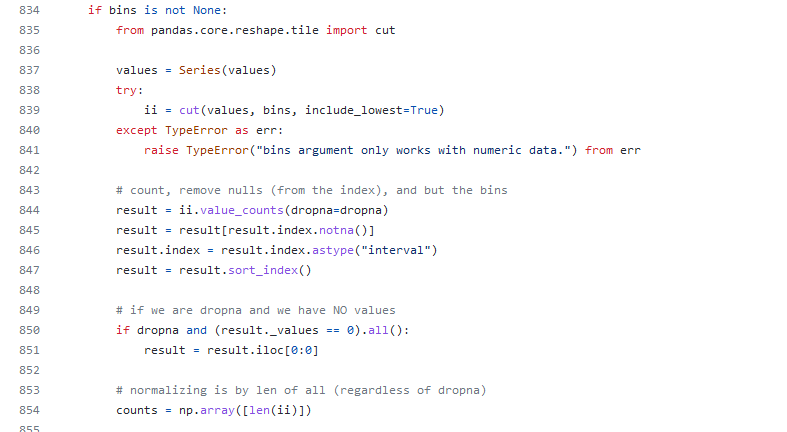 В этом коде бины используются не напрямую, а путем сортировки и удаления пустых значений. Это довольно сильно меняет результат, так как сортировка идет по количеству, а не по границе бина.
В этом коде бины используются не напрямую, а путем сортировки и удаления пустых значений. Это довольно сильно меняет результат, так как сортировка идет по количеству, а не по границе бина.
Разумеется, документация в таких случаях молчит. Корректным выходом может быть:
res=pd.Series(arr).value_counts(bins = bins, sort=False,dropna=False)
Сейчас можно бежать проверять свой pandas.cut и еще с десяток узких мест в коде. А можно доверить разработку скоринга профессионалам.
Выступление лидера команды raisk.ru Владимира Козлова на форуме Scoring Day X, проведенном 16 сентября 2021 г. порталом FutureBanking.ru ( ИД "Регламент")
.